In older posts on this blog I showed that Java’s performance can come pretty close to C – at least for simple numeric benchmarks. Android’s Dalvik VM is often blamed for its bad performance, though things have improved since the introduction of a JIT. With all that HTML5 vs. native debate and the ongoing Javascript hype I though it would be cool to run some benchmarks and compare the performance of Java, Javascript and C on my notebook, an iPhone 4S and a Google Nexus 7.
I decided to run a mandelbrot benchmark first. This time I wanted to see a nice colored mandelbrot set and found a Javascript version on http://www.atopon.org/mandel/# . I decided to bring that source code to Java and C (no SSE intrinsics, just plain C code to support all platforms). Here are the results showing the duration in milliseconds for each language and platform: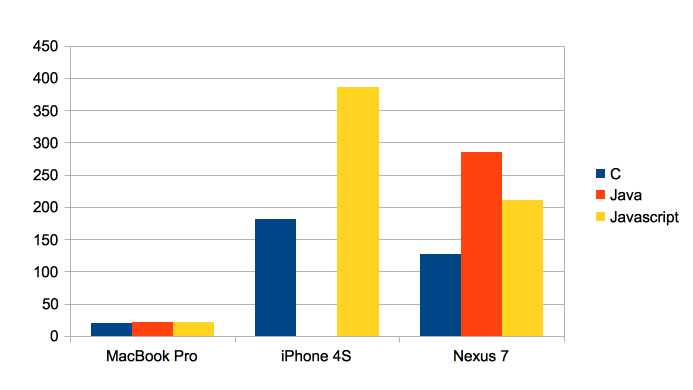
- On the MacBook Pro the performance is within a narrow range. C wins with 19 msecs, Java is second with 21 msecs and Javascript is amazingly quick with 22 msecs.
- On the iPhone the Javascript Nitro Engine takes 113% more time that the C version. Nevertheless almost factor 2 isn’t too bad for a dynamic language.
- The most surprising result was on the Google Nexus 7. C was fastest, the Java code on the Davlik VM was 144% slower and the V8 Javascript engine achieved to beat the Dalvik VM significantly. The first computation was 65% slower and after that warm up subsequent computations were only 42% slower than C. Once again: V8 is much faster than Dalvik and easily within a range of 2 to C!
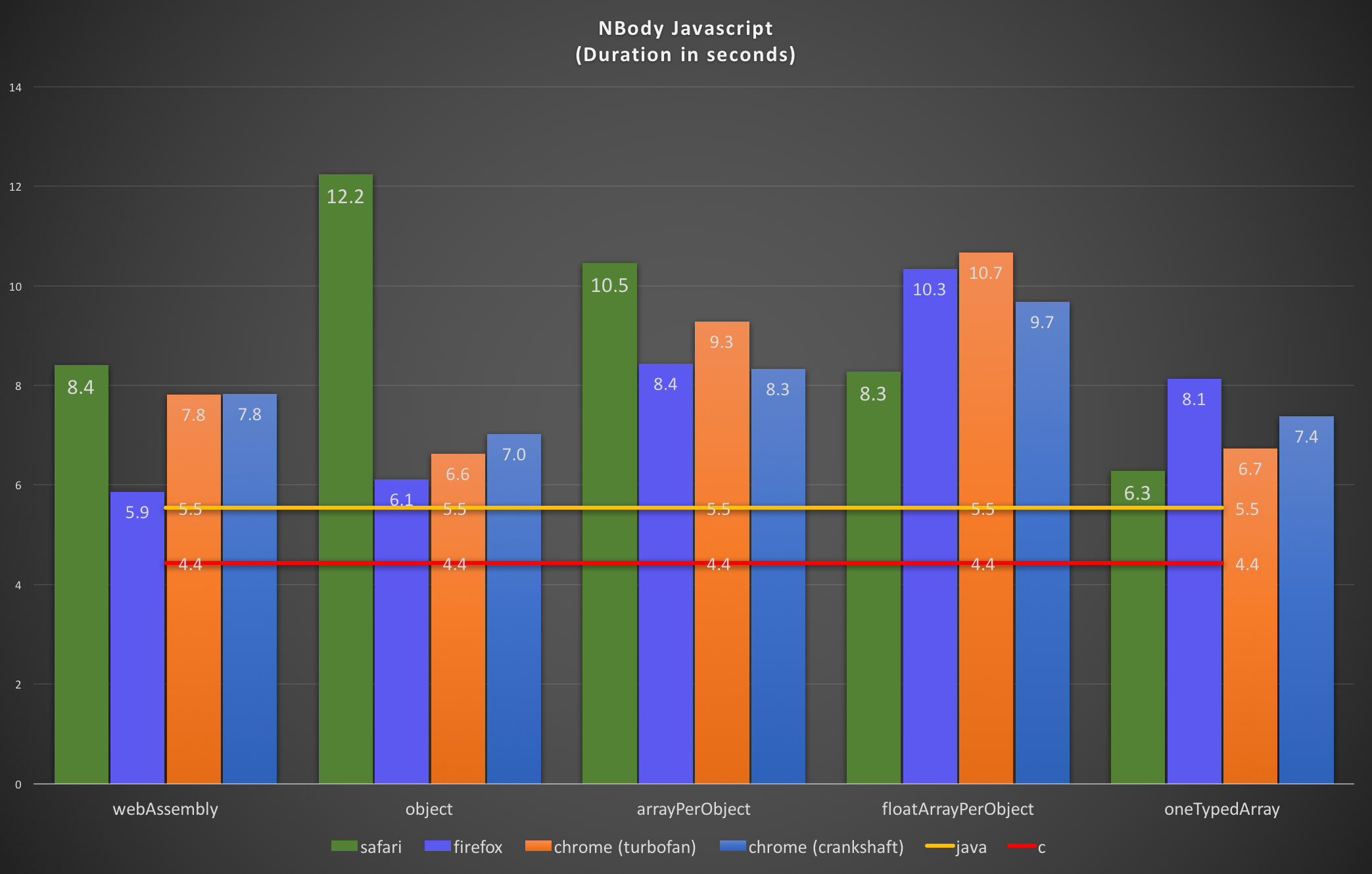
A single benchmark doesn’t prove anything, so why not add another well known benchmark. I took NBody (as I always did on this blog ;-)).
The results for NBody confirmed those results. For C I took the fastest plain C implementation from the Computer Language Benchmarks Game. Once again the y-axis shows the duration (this time in seconds).
- On the MacBook Pro Javascript was 44% slower than C (Java only 1.5%).
- The Javascript Nitro VM on my iPhone 4S was 99% slower than C.
- On the Nexus 7 there’s once again the same image: Java is 106% slower than C, Javascript only 43%. Amazing.
For simple numeric benchmarks the performance of Javascript is simply astonishing. On the MacBook Pro Javascript is incredibly close to the performance of C and Java. On the iPhone Javascript was within a range of factor 2.1. For me it was very surprising to see V8 on Android being able to beat Java on the Davlik VM by a large margin.
Fine print:
- Slower and faster usually cause headaches in benchmarks (There a nice paper about that http://hal.inria.fr/docs/00/73/92/37/PDF/percentfaster-techreport.pdf). I sticked with the elapsed time, such that e.g. 42% slower means that the factor of the durations was 1.42.
- On the MacBook Pro C was compiled with clang using -O3 -fomit-frame-pointer -march=native -mfpmath=sse -msse3 for x64. Java was Oracle Hotspot 1.8.0-ea-b87 on 64 bit (thus C2 aka Server Hotspot). Chrome was 28.0.1493.0, but the 32 bit version. I tried to compile V8 myself, but both the x86 and x64 custom built V8 were significantly slower than Chrome so I stick with Chrome.
- On the iPhone I used a release configuration using clang with (among others) -O3 -arch armv7
- The Google Nexus 7 runs Android 4.2.2, Chrome 26.0.1410.58. C was compiled with -march=armv6 -marm -mfloat-abi=softfp -mfpu=vfp -O3.