WebAssembly gives us the promise to run high performance code in the browser in a standardized way. Now that there are a few WebAssembly previews available I decided it’s time to take a look at their performance. One source for benchmarks is the well known Computer Language Benchmarks Game and I decided to pick nbody (it’s almost four years ago since I did so last time…).
After playing a bit with the results I decided to put the code on github. I’m looking forward to your corrections, improvements and feedback. I’m already excited what the results will look like in a few months…
The following versions were compared:
- webAssembly: A WebAssembly version compiled from the original c version, because this turned out to be faster than the other version I checked
- object: The fastest javascript version from the Computer Language Benchmarks Game. It uses a javascript objects for each body to store the data.
- arrayPerObject: Each body’s data is stored in a plain javascript array.
- floatArrayPerObject: Each body’s data is stored in a typed array
- oneTypedArray: All body’s data is stored in a single typed array and the advance function is programmatically unrolled (quite crazy, isn’t it).
- To get a baseline the fastest java and the original c version were added.
Here are the results:
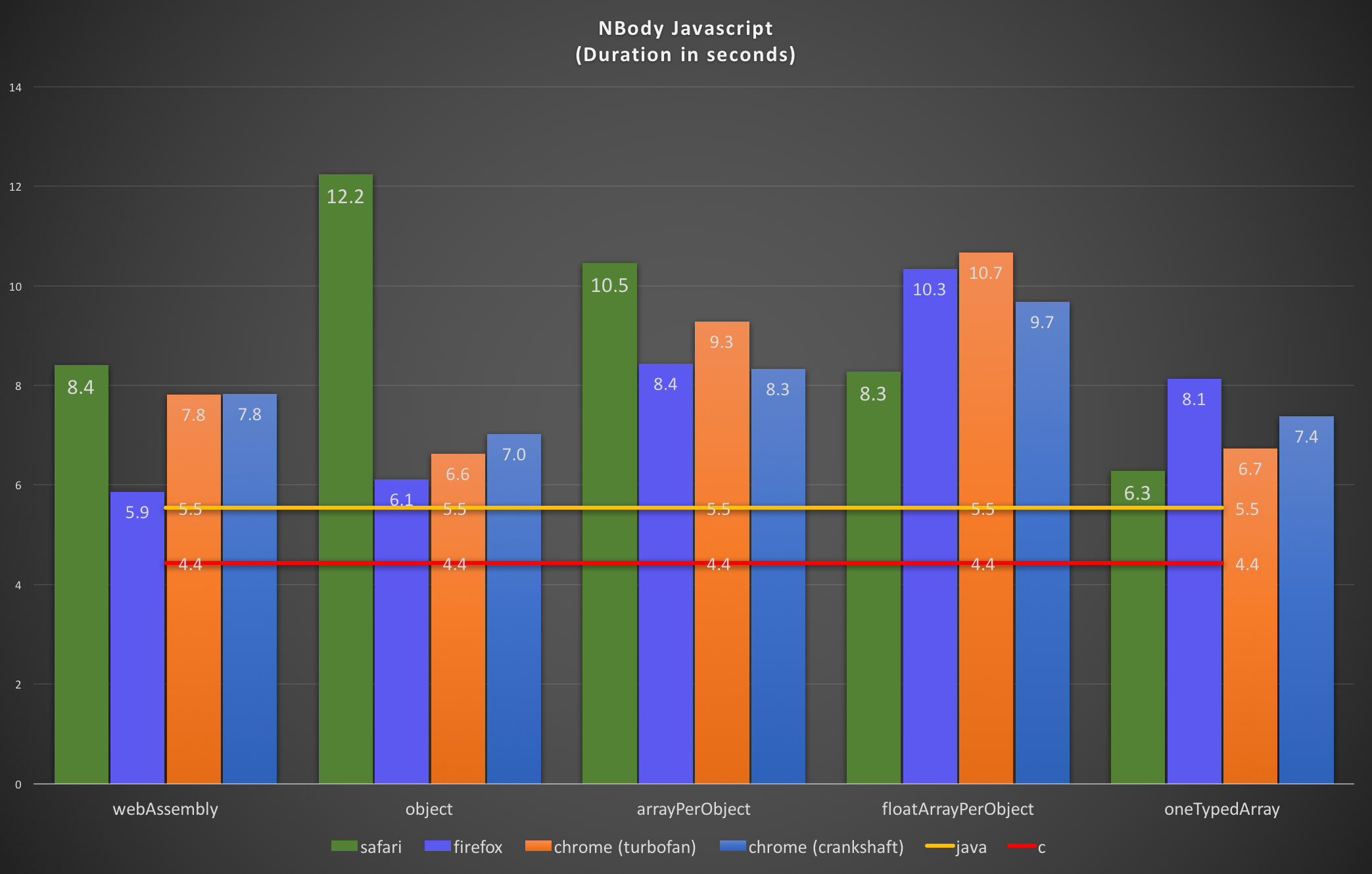
Firefox does pretty well. The WebAssembly implementation is the fastest browser version and close to the java baseline, but the pure javascript implementation isn’t really much behind. Seems like Javascript VMs are already pretty good at simple numeric code.
For the other browsers WebAssembly couldn’t beat the javascript versions yet. And Safari has a completely different idea what Javascript version it can optimize best.
The fine print
Browser versions:
- Chrome Canary, 58.0.3004.0, invoked with
--js-flags="--turbo --trace-opt --trace-deopt --trace-bailout"
for turbofan and
--js-flags="--trace-opt --trace-deopt --trace-bailout"
for crankshaft.
- Firefox 53.0a2 (2017-02-06) (64-Bit)
- Safari Technology Preview Release 22 (Safari 10.2, WebKit 12604.1.4.2)
WebAssembly setup:
- Emscripten and Binaryen were installed as described on Compile Emscripten from Source. (emcc (Emscripten gcc/clang-like replacement) 1.37.2 (commit 70d370296036cc5046083a3e215cb605c90e004b))
- The c source code was compiled with that command:
emcc nbody.c -O3 -s WASM=1 -s SIDE_MODULE=1 -o nbody.wasm
C compiler:
- The c version was compiled with gcc -O3 nbody.c -o nbody (which is Apple LLVM version 8.0.0 (clang-800.0.42.1))
This version took 4.4 seconds on my machine and was faster than the fastest C version from the shootout, compiled with gcc -O3 -fomit-frame-pointer -march=native -mfpmath=sse -msse3 nbody_fastest.c -o nbody_fastest, which took 4.9 seconds on my machine
Infrastructure:
All tests were performed on a 2015 MacBook Pro, 2.5 GHz Intel Core i7, 16 GB 1600 MHz DDR3. For all tests the best of three runs was selected for the result.