
About half a year ago I published my first results for a C vs. JVMs benchmark. Some version updates appeared since then and so I thought it’s time for another run.
Some words about the benchmarks
Four of the five benchmarks stem from benchmarks found on the The Computer Language Benchmarks Game. They have been modified to reveal the peak performance of the virtual machines, which means that each benchmark basically runs 10 times in a single process. The first run might be negatively influenced by the JIT compiler and isn’t counted and only the remaining 9 times are used to compute the average duration.
The fifth benchmark is called “himeno benchmark” and was ported from C code to java. Himeno runs long enough such that the warm up phase doesn’t matter much.
Compilers and JVMs used in this comparison
- GCC 4.2.3 was taken as a performance baseline. All programs were compiled with the options “-O3 -msse2 -march=native -mfpmath=387 -funroll-loops -fomit-frame-pointer”. Please note that using profile guided optimizations might improve performance further.
- LLVM has just released version 2.3 and is a very interesting project. It can compile c and c++ code using a GCC frontend to bytecode. It comes with a JIT that runs the bytecode on the target platform (aditionally it even offers an ahead of time compiler). It is used for various interesting projects and companies like most noteably apple for an OpenGL JIT and some people seem to work on using LLVM as a JIT compiler for OpenJDK. I used the lli JIT compiler command with the options -mcpu=core2 -mattr=sse42.
- IBM has released it’s JDK 6 with it’s usual incredible bad marketing (of course there’s no windows version yet). I’ve used JDK 6 SR1, but I couldn’t find a readable list of what changes it includes. The older IBM JDK 5 is also included to see if it was worth the wait.
- Excelsior has released a new version of it’s ahead of time compiler JET. Both version 6.0 and 6.4 have been benchmarked. JET is particularly interesting because it combines fast startup time and high peak performance and is therefore just what you’d expect from a good desktop application compiler.
- Apache Harmony is also included in the benchmark. It’s aimed to become a full APL licenced java runtime and used for the google android platform. Recently the Apache Harmony Milestone 6 was released. I’ve taken a look at this version’s performance in this blog.
- BEA JRockit is no longer included due to a great uncertainness about it’s current and future availability. A short period after Oracle bought BEA all download links were removed from the web page. A few days ago it was announced that JRockit will no longer be available as a standalone download.
- SUN’s JDK 6 Update 2 and Update 6 were put to the test with the hotspot server compiler (i.e. -server option).
- All benchmarks were measured on my Dell Insprion 9400 notebook with 2GB of RAM and a intel Core 2 running at 2GHz under Ubuntu 8.04 (x86).
Results
All images below show the duration in milliseconds (i.e. smaller bars are better).
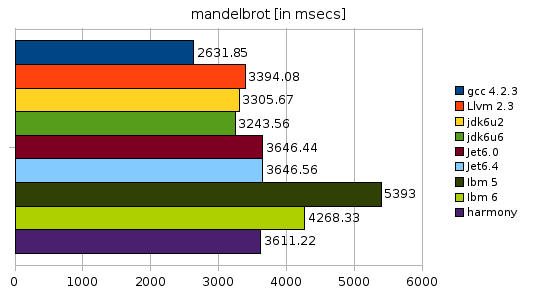
As for mandelbrot GCC stays fastest by a good amount, the difference between Sun JDK 6U6 and 6U2 is negligible. The same is true for JET 6.4 and 6.0. Harmony shows a much improved performance since the last benchmark and close to the competitors.
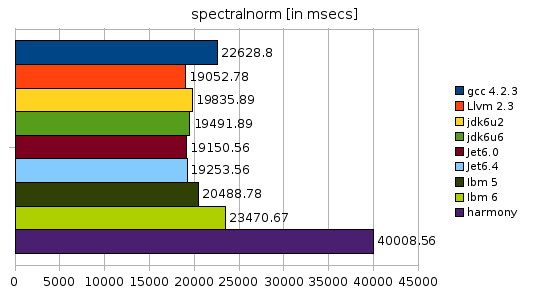
The spectralnorm benchmark is kind of interesting in that LLVM and most JVMs can beat GCC in this particular benchmark. Most notably LLVM comes out fastest. Harmony has improved a bit (but not enough) since the last comparison.
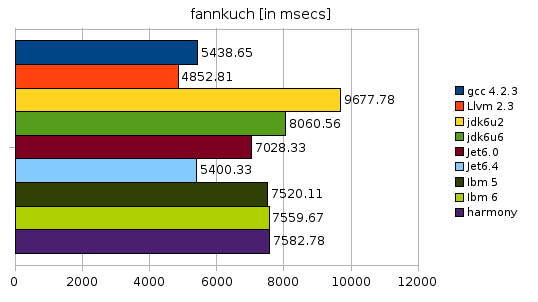
The results for the fannkuch benchmark are much more interesting than the ones before. There are quite large improvements for both SUN and JET. JDK 6U2 performed really weak in this benchmark and 6U6 is a small step into the right direction, but it’s still worse than any other JVM benchmarked. JET 6.4 on the other hand managed to improve such that it runs even a little bit faster than GCC. This is really remarkable since JET runs with bounds checks enabled and fannkuch has quite a few indirect array access operations. And it’s the second benchmark where LLVM shines. (Please note that harmony has been benchmarked with -Xem:opt. The -Xem:server option gives better results. The benchmarks runs in 7173 msecs then)
Nbody shows again that it’s possible for JVMs to reach the C++ performance level. There’s a very nice improvement for SUN’s JDK from Update 2 to Update 6 and a small improvement for JET 6.4, which runs the benchmark the fastest. IBM’s JDKs perform quite poor – just like harmony. LLVM also appears to have potential for further optimizations.

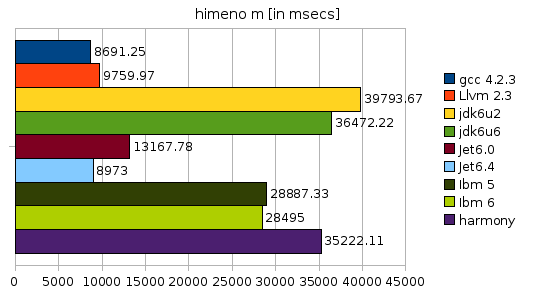
The himeno benchmark is new and really strange. It has a frightening cascade of inner loops with really a lot of array operations. I used the original c version and ported it to java manually inlining a macro used for the array access. The c version is slightly modified to port an optimization regarding that macro back to the c version (thanks Dmitry!).
This is a benchmark that shows just like fannkuch that there are some cases that SUN’s hotspot can’t handle well. GCC runs in less than 1/4 of the time it takes for JDK6U6 to finish! IBM and harmony are better but still far from good. Only JET comes to the rescue for the java world and beats LLVM and gets very close to GCC. The improvement from JET 6.0 to 6.4 is once again very astonishing. (Please not that harmony has been benchmarked with -Xem:opt. The -Xem:server option gives much better results. The benchmarks runs in 24770 msecs then, which means that harmony beats Sun’s JDK and IBM’s VM!)
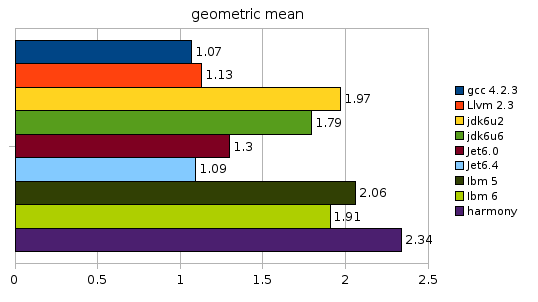
The last diagram is an attempt to summarize the results. I decided to compute for each benchmark the ratio of each compiler/JVM to the fastest competitor and take the geometric average of those figures. The results back quite nicely my feeling about their performance. (The geometric mean for harmony is with option -Xem:opt, -Xem:server yields 2.13)
Conclusion
- Unsurprisingly GCC is fastest.
- Surprisingly it is followed very, very closely by JET 6.4, which delivers the best java performance.
- LLVM does a good job but in contrast to some statements it seems not to beat GCC’s perfomance yet (even without PGO). It’ll be interesting to see how much perfomance will be lost if it’s used as a Java JIT due to bounds and type checking.
- SUN’s JDK has some weak points that can be seen in the fannkuch and himeno benchmarks. Without these two benchmarks the hotspot server compiler would be almost competitive with GCC. Nevertheless JDK 6U6 has gained quite a bit performance in comparison to JDK 6U2.
- Harmony still has a long way to go, but at least some progress can be seen.
- What’s causing me some headaches is that competition between Sun, IBM and Bea (Oracle) seems to be in danger. I’m not too sorry for IBM – I neither enjoyed using their VM on an appserver (guess which one…) nor for those benchmarks, but JRockit was always been a very nice alternative and it’s performance was most of the time superior to SUN’s. So I’m very anxious about Oracle’s direction regarding JRockit. After that start they can’t do much worse.
Resources
- OpenOffice Spreadsheet with all measurement details (incl. confidence intervals)
- Source Code for the benchmarks
very interesting comparison, keep on benchmarking!
It would be also interesting to compare non number crunching benchmarks, like c++ object allocation vs. java. But this is more difficult since there are a lot of VM arguments for tuning.
Hi Stefan
Nice benchmarks. I would be interested to see why the gcc spectral norm test did not fare so well here. As per your last benchmarks, did you do a t-test for test of significant differences between means? If so, what level of significance did you use? Also, it would be interesting to see active memory consumption differences for these tests, not just between gcc and java, but also between jvms.
Rory
Out of curiousity, did you configure llvm-gcc for pentium4 or some other recent platform that supports SSE2? Not doing so would easily explain the poor floating point performance you’re seeing. The code generator is not well optimized for X87 FP stack because so few systems need it. Unfortunately, the GCC build process defaults to i386, not a reasonably modern cpu.
Oh, reading your description more closely, I do see that you are using reasonable options… but why use the JIT?
You should explain here that this is really a CPU benchmark, without the additionnal burden of garbage collector.
You should also test overall efficiency, like memory usage etc.
For the test where java is “faster” than C, there is a simple explanation for this:
the algorithm is not written correctly for both languages or the code is not written optimally, and because the java virtual machine has the so called “hot spot” it optimizes the most critical parts. If you optimize the critical parts in C, then it will surely run faster than any Java code.
C (and other machine code compiled languages) generates machine code, there is nothing faster than machine code.
If java generates machine code for critical sections, it can at best match the efficiently written C code, but if the java equivalent is faster then this means that your C code is inefficiently written, or you are using a better algorithm in Java.
Practical applications don’t just run Mandelbrot, these are “synthetic” benchmarks, try to write a small application in each language and then compare them.
or this means that C compiler is not as good as it can be =)
From these benchmarks one could assume that Java is as nearly fast as C. But
this is only partly true. You should explain here, that Java is lacking
fast structured types. Therefore, many algorithms cannot be
efficiently coded in Java. Using objects for structs is often not
possible because objects consume a lot of extra memory and
objects instantiation takes more than 1E-7 seconds.
CodeAssembly: Excelsior JET compiles Java bytecode to machine code ahead-of-time, yeilding a conventional Windows or Linux executable. As of version 6.4, it may also collect an execution profile during a so called Test Run before compilation to native x86 code, but it does not use that information to better optimize code yet. The profile is only used to reorder pieces of the executable to reduce the cold startup time.
Christoph: This is a good point. What the results of benchmarking suggest is that you should not discard Java “because it is inherently slower than C”. It may or may not be inherently slower than C for a particular algorithm, or require substantially more memory than C.
Pingback: Excelsior blog » Blog Archive » Java vs. C Benchmark: Excelsior JET 6.4 Scores an Equalizer
Oracle will continue to support and invest in JRockit, so there shouldn’t be any uncertanties there. Some downloads here, and see the FAQ for more information:
http://www.oracle.com/technology/software/products/jrockit/index.html
IBM’s JVM for Windows is not available standalone except if you’re running on IBM hardware, but you can extract it from the IBM Development Package from Eclipse. The reason for this distribution model is not officially available, but it’s likely due to restrictions in the IBM’s Java license. Or in other words: Sun doesn’t like competition in the Java SE space.
Henrik, Oracle JRockit team
Hmm, what about compression? Take a look on http://www.quicklz.com/ – they benched their library to prove how fast it is.And Java version is lot slower (up to several times).Is this still true for modern JVMs? Can’t you create same style behchmark to see how JVMs performing when both computations and access to memory matters?
To Henrik:
Speculative assumptions are good for JIT compilation, not for reasoning about competition. ;)
To Stefan: Yes, please add JRockit to the charts at your earliest convenience. I’m very glad to hear that Oracle has decided not to shut it down. It’s good for competition ( Am I correct, Henrik? ;)
–Vitaly Mikheev, Excelsior Java Team
Thanks, Stefan. Keep on benchmarking!
I’m going to look into Harmony performance on these tests, at least spectralnorm looks strange :)
use -O3
my Intel(R) Core(TM)2 Duo CPU L7300 @ 1.40GHz done this test in 2 times faster, then in your test.
and try to calc used memory
You will be surprised
Tolik,
Be more precise. Memory usage is a instantaneous value which can be calculated
at a *moment*.
I see the following possibilities for quantitative evaluation:
1) Memory usage at certain moments of execution (samples)
2) Peak memory usage
3) Approx. integral value of p.1 for the entire period of exection (depends on the frequency of samples)
What kind of “memory usage” do you mean?
–Vitaly
I took your nbody_long.java and have modified to replace all instances of:
(number*number*…)
to
Math.pow(number, n)
and have 10 times performance increase.
Sorry, but what is the point of comparing C/C++ and Java? They are used for different task. Java is never used on where performance is critical. While C/C++ is hardly used as a web application language.
> I took your nbody_long.java and have modified to replace all instances
> of (number*number*…) to Math.pow(number, n) and have 10 times
> performance increase.
I’ve done the two things:
(a) replaced (distance*distance*distance) to Math.pow(distance, 3)
(b) replaced (x*x) to Math.pow(x, 2)
Results on Sun 1.6.0_05 -server on Core2Duo 1.8Ghz (3 warmup, 1 measurement iteration):
Baseline: 578 msecs
Version (a): 3656 msecs
Version (b): 5331 msecs
Thus, this one is performance degradation rather than improvement.
As Chris pointed out, and you note in your post, LLVM has a static compilation mode in addition to JIT. Since the JIT tool does not perform any JIT-specific optimizations (those are to be determined by the client of the LLVM libraries), the JIT will be strictly slower than ahead-of-time compilation. It is with respect to ahead-of-time compilation that LLVM is usually compared to GCC, so your comment in that respect is somewhat misplaced.
@Owen, Chris: I’m discarding the data of the first run (thus the cost of JITing is not measured). Does the AOT compiler apply better optimizations than the JIT?
@Henrik: Good to hear that JRockit has a future. The FAQ clears my questions. I’ll include JRockit in future reports. Maybe you can fix himeno_bench m till then ;-) I’ve measured 44840 msec running an x86 (x86_64 is half as slow).
@Aleksey: I forgot to mention that I used the -Xem:opt option. This seemed faster than the -Xem:server mode
And I didn’t mention the input data:
mandelbrot: 4000 4001 4002 4003 4004 4005 4000 4001 4002 4003
nbody: 19900001 19900002 19900003 19900004 19900005 19900006 19900007 19900008 19900009 19900010
spectralnorm: 5501 5502 5503 5504 5505 5506 5507 5508 5509 5510
fannkuch: 11 11 11 11 11 11 11 11 11 11
himeno_m: M
I tested c++ code in my desktop computer with Core2Duo E6750, 1333FSB, memory 1066 with 5-5-5-15.
I used Visual Studio 2005, default Release building, and used GetProcessTimes for fix times (it fixes only time used by the process, as getrusage in linux,…).
I tested spectralnorm benchmark and made some changes in the code.
I ran with arguments: 5000 10000
You have the following result between gcc and llvm: 19052/22628 = 84.2%
your original code (duration in ms):
1.274224153
duration |16656|
1.274224153
duration |65140|
I replaced fill(u.begin(), u.end(), *); by for(int j=0; j<N; j++) u[j] = *; as you wrote in java code. Results:
1.274224153
duration |14671| – 88% of original
1.274224153
duration |58296| – 89.47% ..
After that I inlined eval_A. Results:
1.274224153
duration |14328| – 86%
1.274224153
duration |53500| – 82.1%
code:
LETS GO FURTHER!
I do believe that java have good memory manager. And decided to made global (the main’s variable which I passed to the function as third arg) ‘vector v’ in eval_AtA_times_u. Also I inserted Au[i] = 0; in eval_A_times_u and eval_At_times_u for getting the correct results as you wrote in java code. Results:
1.274224153
duration |11687| – 70.2%
1.274224153
duration |46687| – 71.7%
Last result is better than original gcc/llvm ratio.
I do believe that there are just inexact (inaccurancy) conversion to c++.
In other hand it will be cheaper to buy computer with enough capacity instead of hiring expensive good c++ programmer.
2 Aleksey Shipilev:
I didn’t used -server option and run it on Java 6u6/Windows XP/Core2Duo and have 10 times better performance with input 999999. But at home on AMD 5600+/Ubuntu/jdk6u6 I got a degradation.
@admin: I’m a little confused by throwing out the first timing. Did you modify the benchmarks to execute themselves multiple times? LLI doesn’t cache translations across executions, so I can only assume that’s what you did.
Also, could you post what flags to llvm-gcc you used? I assume you passed -O3?
@Owen:
Yes, the benchmarks from the language benchmark game are modified to execute multiple times in one execution.
Most Java guys consider it important not to benchmark the warmup run, because hotspot executes the first invocations in a profiling interpreted mode and optimizes only blocks that were executed often. To measure the peak performance one has to perform a warmup run and then run the benchmark in the same VM instance – or use at least a benchmark that runs long enough (this is used for himeno).
I used pretty much the same options for LLVM that I used for gcc (knowing that some might be ignored):
/home/stef/progs/llvm23/bin/g++ -O3 -msse2 -march=native -mfpmath=387 -funroll-loops -fomit-frame-pointer -c -emit-llvm -o spectralnorm_llvm src/spectralnorm_long.cpp
@ilnar:
I appreciate the computer language benchmark game for allowing people to send optimized implementations, such that the code should have been tested by some people. The spectralnorm benchmark was derived from a C++ and Java version from that benchmark. You might also look at the spectralnorm benchmark on my first benchmark (http://www.stefankrause.net/wp/?p=4) where intel C++ was much faster than GCC. So I’m not surprised that MSVC can do better. If you look at the computer language benchmark you’ll also notice that the c++ compilers can sometimes differ a lot depending on the code (e.g. mandelbrot C++ Intel #3 and C++ GNU g++ #3 program)
Yours,
Stefan
@IvanoBulo
>2 Aleksey Shipilev:
>I didn’t used -server option and run it on Java 6u6/Windows XP/Core2Duo and have
>10 times better performance with input 999999. But at home on AMD 5600+/Ubuntu/jdk6u6
> I got a degradation.
1. -server is required for throughput-intensive benchmarks.
2. You should always explicitly supply -client/-server while benchmarking, because you might be hit with Server-Class Machine Detection: http://java.sun.com/j2se/1.5.0/docs/guide/vm/server-class.html
3. Can you show your benchmarks? Say, mail them to aleksey.shipilev[doggy]gmail.com along with “java -version” output. I’m very interested in your results :)
@Admin:
> I forgot to mention that I used the -Xem:opt option. This seemed faster than
> the-Xem:server mode
I’m very sorry to hear that. -Xem:server enables profiling and profile-guided optimizations, while -Xem:opt does static optimizations only. But Harmony lacks on-stack replacement so the benchmark with _one_ hot method may always execute the code under profiling. Anyway, looking into the Java benchmark code I see there should be no problems. Can you shred more light on this comparison?
Stefan,
Thanks for sharing your findings. We (HotSpot) will be looking at several of these, i.e those we don’t do very well on to see what we can do to improve.
Would you be interested in re-running the HotSpot tests with -XX:+AggressiveOpts?
We tend to introduce new performance optimizations under this command line switch. We do this for stability reasons. For example, those desiring stability over performance can run without specifying -XX:+AggressiveOpts. Those wanting additional performance can specify it explicitly. In other words, we tend to favor stability over performance. Btw, what’s the performance of a crashed VM? ;-)
charlie …
@Aleksey: I’m sorry to say that my statment isn’t true. -Xem:opt is faster than -Xem:server for mandelbrot and nbody (but Nbody has a very large variation! The conficence interval for 97.5% are almost 11 secs large). For spectralnorm the results are almost equal. For fannkuch and himeno the -Xem:server is faster. For himeno even my a large amount! The next time I’ll use -Xem:server. Sorry for devaluating harmony’s performance. I’ll update the text to at least mention the better results for -Xem:server
First number is -Xem:opt, second, the second is -Xem:server
mandelbrot: 3611 vs. 3864
nbody: 25302 vs. 29121
spectralnorm: 40009 vs 40000
fannkuch: 7583 vs 7173
himeno_m: 35222 vs 24770
Charlie, that’s very good to hear!
I’m always interested in promising options or new versions…
Here are the results for -server vs. -server -XX:+AggressiveOpts for Sun JDK 1.6 Update 6:
mandelbrot: 3244 vs. 3242
nbody: 11694 vs. 11663
spectralnorm: 19492 vs. 19542
fannkuch: 8061 vs. 7972 (it’s the only benchmark where the 2nd run is significantly slower than the others)
himeno: 36472 vs 39023
Except for himeno the results are not significantly different. For himeno the 97.5% confidence intervals range from 36461 to 36484 msecs for -server and 38954 to 39103 for -server -XX:+AggressiveOpts, i.e. AgressiveOpts seems to make that benchmark slower.
Stefan,
Thanks for running the benchmarks with AggressiveOpts. We are currently looking at the source code along with the (JIT) generated code to see what additional general optimization opportunities might exist..
thanks,
charlie …
@Admin:
It’s weird that -Xem:opt runs faster on nbody and mandelbrot. -Xem:opt is used for debugging purposes for now, so nobody actually benchmarking in this mode. This is great opportunity actually – that’s the thing to explore for Harmony. Thanks, Stefan, for this occasional finding :)
We are actively working on performance tuning, so it would be great to review Harmony performance by 3rd party (you!) again some day :)
@Admin:
Forgot to say, Harmony accepts -server as the alias for -Xem:server, so you can throw the doubt next time and use the same cmdline as for other JREs.
> a C vs. JVMs benchmark
spectral-norm source seems to be C++ not C?
> I appreciate the computer language benchmark game for allowing people to send optimized implementations …
since you first took source code from the benchmarks game faster programs have been contributed.
Stefan,
I’m having trouble reproducing your himeno results. I just added a copy of himeno (hacked to fun the benchmark a fixed number of times, rather than an adaptive number) to our nightly testsuite, and am consistently seeing LLVM outperform my system GCC by a factor of 1.9x. Check out
http://llvm.org/nightlytest/fulltest.php?machine=296&night=6680
It’s somewhat hard to decipher (and may take forever to load), but look for the Benchmarks/Himeno/himenobmtxpa row, and compare the “GCC” and “LLC” columns. The former represent the time to run the test compiled with GCC, and the latter the time to run it compiled with LLVM. You’ll notice that the GCC time is 5.69s while the LLC time is 3.17s.
That doesn’t exactly match up with your results. ;-)
Would it be possible for you to post a copy of your modified himeno so I can try to figure out what’s going on?
Ah ha! Figured it out!
It turns out that link-time optimization (LTO) has a very large benefit for himeno. Here’s an amended procedure to use to get LTO:
llvm-gcc -O3 -msse2 -march=native -mfpmath=387 -funroll-loops -fomit-frame-pointer -c -emit-llvm -o himeno_llvm.bc src/himeno.c
llvm-ld -native himeno_llvm.bc -o ./himeno_llvm
./himeno_llvm
Or, if you’re using Mac OS X with Xcode 3.1, you can just use /Developer/bin/llvm-gcc -O4 and skip the llvm-ld step. This is because, as of Xcode 3.1, the OS X system linker supports LLVM’s bitcode format natively. Hopefully someone will implement this for the Linux linker one day.
If you follow those steps, you’ll see a pretty major increase in performance, at least for himeno.
Java version of specnorm is better optimized (less pessimized) in code:
array size n is passed directly to the inner functions, not calculated there anytime as u.size();
for (int i = 0; i < n; i++) v[i] = 0; is moved out of the 10 times loop.
Some better optimization is possible in multiplication routines: in the loop by j we can add not to the array element Av[i], but to a local variable Avi, that would be put into the array after the loop.
Why you use option -fpmath=387? SSE works faster, and, probably, is used in Java VM.
After eliminating these differences, g++ program runs a little bit faster than the java one. It can’t be much faster, because most time here is required by the division, so this test is just a measure of processor FPU speed.
Stefan,
I just changed C++ implementation for gcc and it now looks like java code.
A few reason why java code appears faster than c++ it’s difference between the code.
I figure out that some of loops in java code were ported to C++ incorrectly.
And there is no matter what I used, gcc or msvc, I just reported ratio between incorrectly ported code and the code after corrections. Corrections consist only fixes that make c++ and java code almost the same.
Stefan, have you read this article
http://www.ibm.com/developerworks/java/library/j-benchmark1.html
yet?
You may want to consider using the benchmarking framework described therein, and which is freely available for download. Benchmarking dynamic JVMs is really tricky, with a lot of gotchas. This framework handles all of the warmup issues, and generates proper statistics (or warns you that the stats are worthless).
Have you tried the Java SE 6u6-p “Performance Release”? (is not the same as the one you tried, its version number is “1.6.0_06-p”).
It is already available for almost all platforms and its improvements in some things are incredible… You can download it from [“https://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_Developer-Site/en_US/-/USD/ViewProductDetail-Start?ProductRef=jdk-6u6-p2-oth-JPR@CDS-CDS_Developer”].
P.S: Is that lins doesn’t work you must start navigating from the link dated in july’08[“http://java.sun.com/javase/technologies/performance.jsp”]
Stefan,
Wonderful work, please keep it up!
Question: why was GCJ excluded from this round of benchmarking? Is it because they haven’t rereleased since your last benchmark? At a glance, looking at your previous post, GCJ seems to compete with the top performers in most of these benchmarks. Given that GCJ is free, and JET is commercial, that makes me wish it was included in all the benchmarks here!
Pingback: BlueJ contra Python | hilpers
Pingback: Java Faster Than C ? | keyongtech