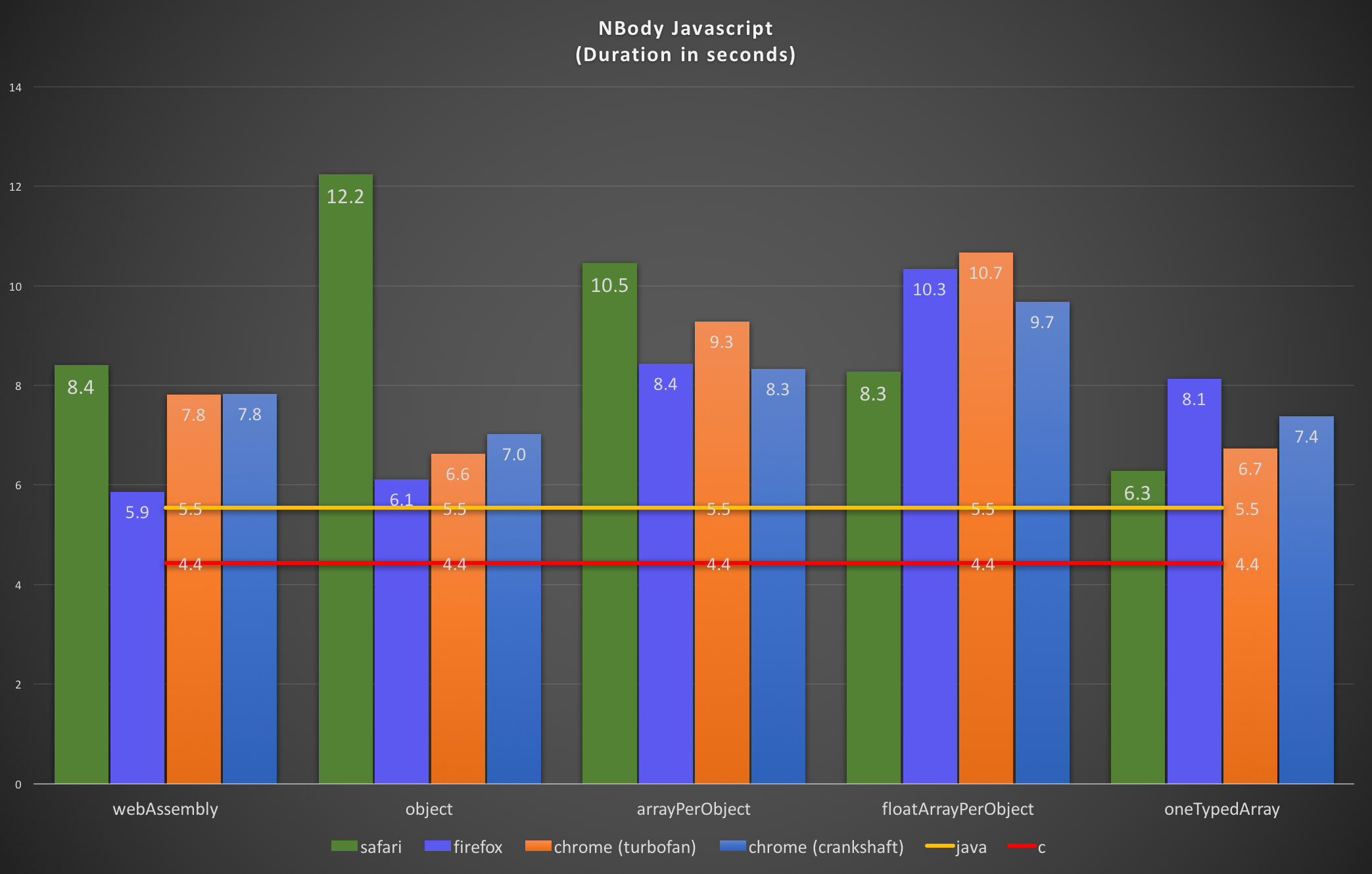
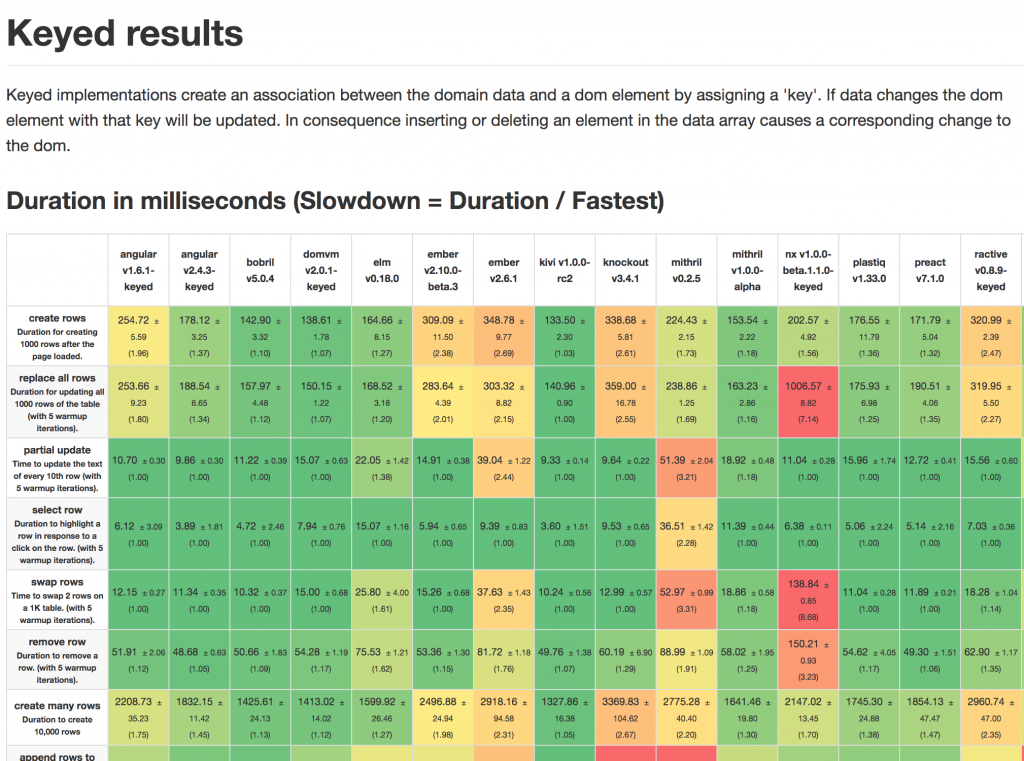
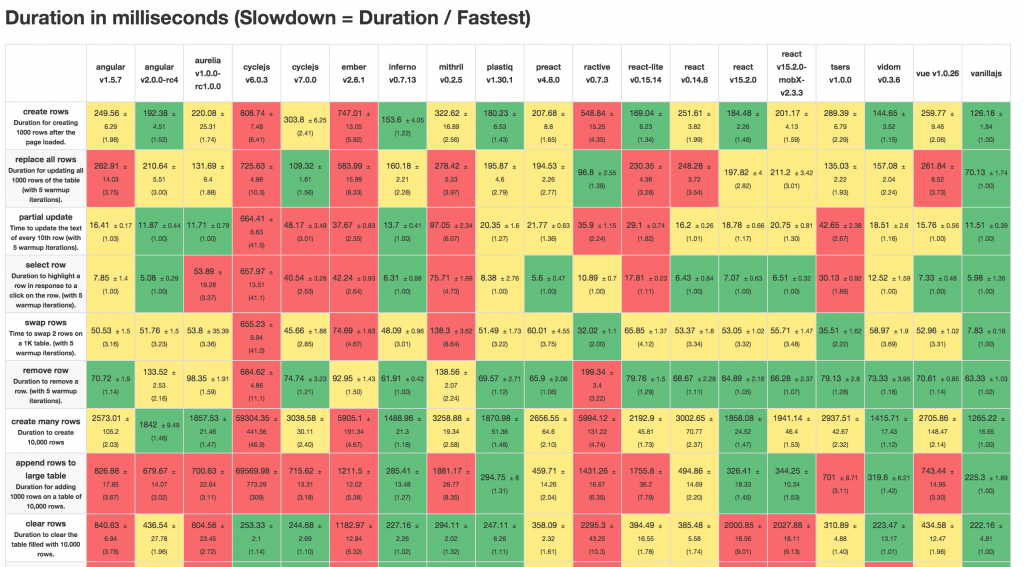
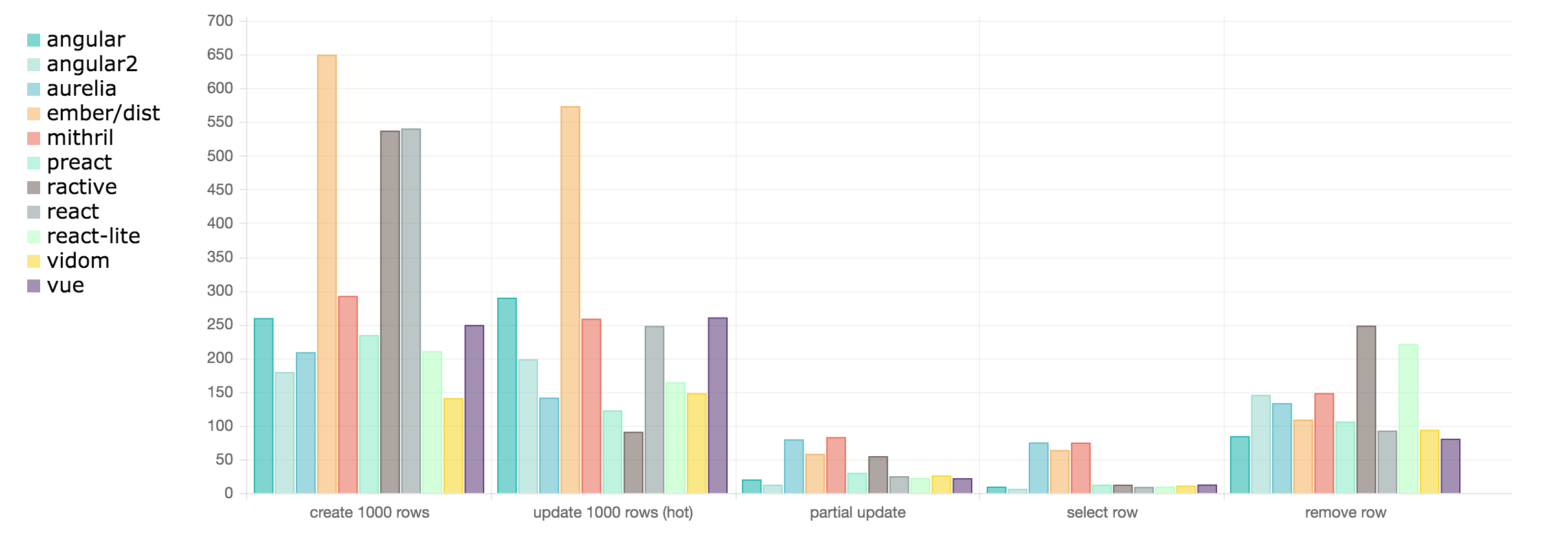
The last round was published more than half a year ago. Time for an update.
The js-framework-benchmark tries to compare the performance of web frameworks by measuring the duration for different operations on a large table like the duration for creating the table, updating, selecting or removing a row and appending rows.
The first round included 9 implementations. In Round 8 there are now 101 implementations. The project grew to more than 300 pull requests from contributors and 2,000 github stars. Thanks to everyone who contributed so far. It’s clear by looking at the number of implementations that keeping them up to date wouldn’t be possible without your contributions.
Keyed and non-keyed
A pretty significant milestone was the separation of keyed and non-keyed frameworks in round 5 (thanks to Leon Sorokin, author of domvm, for the guidance). As it’s an important concept to understand I’ll explain it here again in simple terms.
A framework can implement an update for a list of data in two ways. Either keep an association between a list element and a dom node (which is the keyed mode) or rearrange and reassign the DOM nodes as it wants to (non-keyed).
If you’re using CSS transitions or third-party frameworks non-keyed might cause problems, because e.g. removing an element might instead remove the last element from the dom node list and patch all others to display the correct values. This can cause problems when e.g. CSS transitions styles depend on removing the specific dom node.
Most (maybe al) keyed framework can behave non-keyed if one assigns the list’s array index as a key.
From the framework perspective handling only non-keyed updates makes dom reconciliation much easier. If you want my opinion: Choose a framework that supports keyed updates.
What has changed since round 7?
- Added the first webassembly frameworks in this benchmark: stdweb and yew
- Lots of small and fast frameworks were added: domc, stage0, solid, attodom
- A webcomponent variant for vanilla-js
- A fast alternative renderer for Knockout: ko-jsx
- Significant Improvements for good ‘old’ Marionette.js
- Updates for many others including angular 6 and a preview for the new angular ivy renderer
- Update to the startup metrics. They now simulate a mobile device and use the latest lighthouse version.
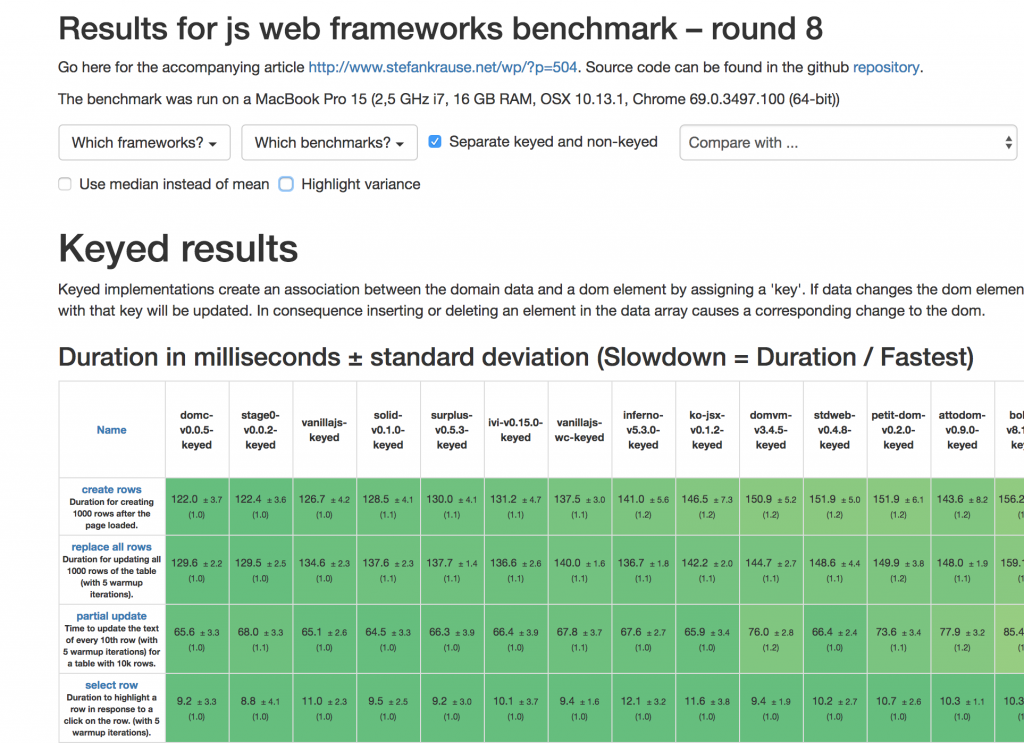
Important results:
- The fastest frameworks are very fast. I have an unresolved issue to “make vanillajs great again”. I can’t beat domc and stage0 and solid, surplus and ivy are very, very close.
- Marionette made a significant jump. The first implementation for version 3.3.1 was about 248% slower than the then fastest pure javascript ‘vanillajs’ version. Version 4.0.0-beta.1 is only 24% slower than domc.
- The (low level) webassembly framework stdweb is only 13% behind. Might be interesting to see how they continue.
Here’s the complete table:
Discuss this article on reddit.